
At this point should not be anything new that I'm playing with my own Mastodon instance. It is meant to be focused on a village in the core of Catalunya, so the scope is so small that I'm alone there 🤪
This also brings me the opportunity to work towards some goals kinda freely: get as much related content as possible, as much automated as possible. So next direct step is: from whom can I get more content? And then, how? Once you answer the first, the second usually comes as a bot getting content from RSS feeds or other Mastodon or Twitter accounts. And because life is not fun otherwise, let's reinvent the wheel and do everything from scratch: a bot to get and publish content to Mastodon.
Disclaimer
No, I'm not going to do a set-by-step about how to do bots. This is going to be a somehow high level article on what is it, what needs to be done, and some tips and tricks I found on-the-go.
I published the code of my bot in my GitHub account (yes, it's public!) and because I am actively using it, it is maintained and I plan to cover it with tests and the typical stuff from my trivago's Collection team's Quality Standards on Python code ™️, even at the moment is not yet there.
Bot Overview
The very first thing is to have clear what do you want this bot to do, what is the goal?
- I want to get data from somewhere and post it through an account in Mastodon
mmm... ok, just go deep one more level: What "data" and which "somewhere"?
datais content, text and maybe images.somewherecould be any of the following, not sure yet. I would love to have a system that once it's done, I just need to crawl internet to discover sources and I set them up in the bot: News and tweets in the official page of the mayorship of the village, news and tweets in the regional newspapers related to the village, maybe the press is already in Mastodon...
That is cool to know. Now next steps:
- Where does it need to run?
- What options does the output give me to tailor all of these above?
That is easy: It can run in my Raspberry Pi at home or directly in the hosting for the Mastodon instance I have. Mastodon has plenty of options: just check this official page regarding Libraries and Implementations. As I use Python daily nowadays I'll use the Python wrapper lib that has the documentation here.
And how do I make it run? That's also simple: a scheduled run of the Python script should be enough. Batch processing FTW.
So, wrapping up:
- A Python script that gathers all content, processes it (whatever it means at this point), and publishes it through a Mastodon account.
- Well need to consume RSS feeds and the APIs of Twitter and Mastodon. This means 3 sources for basically the same action, maybe we can abstract it.
- It will be sitting in any host of my own running scheduled via
crontab
Setting up a Mastodon publishing account
I can make a bot that behaves with my own account or I can create a dedicated account for it so that I does not disturb my own timeline. I prefer the latter, so I need to:
- Create a new account in my Mastodon server and log in to it.
- It is appreciated that bot accounts have marked the "I am a bot" checkbox in the
Preferences - Under the
Developmentsection in thePreferences, create a new App. For the URL I used the one from the Github project, and I left the default permissions.
Depending on how you program your bot, you can use your user/pass to get the keys, store them and re-use them in every run, or you can directly get them from the user's development preferences, store them and re-use them. In the latter case, just see/edit your app and you'll see the keys of this app that you need to have granted access to the account.
Implementing the bot
Even this is the most fun part of the story, it is also the part that gets closer to your own style. So there is not too much to say here more than: program, research, discover, try, fail, retry, get coffee, ... and sleep!
I just want to share some points that helped me, or that I struggled and I think are worth mentioning:
Log log log and log
One of the very first things I realized is that a bot runs alone in the dark and I only want to know what's going on when it fails. And usually by then it's too late. So I kinda fill my code with debug and info (and few warn) messages and I lowered the log_level down once the debug phase is over.
Having a good logging system also helps when implementing as you can direct the log to stdout, so I added also an option to quickly switch it on/off.
Dry run!
While developing, I quickly implemented a main switch for avoiding any kind of publishing before the bot and myself are ready, while mostly all corners of the code are executed. It is very helpful so that gathering content and the processors are executed and I can see the output ready in the queue just before being published.
No DB
That was a strong requirement for me: I don't want to do anything with Databases as much as I can avoid it. I find that for scripts at this level, even in a bigger scale, Databases introduce a level of structure but yet also complexity that is not needed and can be easily implemented with files. I developed a set of very simple classes that deals with the basics of read, write, get and set data that fulfils my needs for this and other Python scripts. I include these classes in a separated Python package that I also have published in my GitHub account and included as a dependency in my requirements package. At it's time, I also maintain it as much as I have the need of them, and I plan to cover it with tests and quality standards whenever I have a moment.
Check it out here: XaviArnaus / pyxavi
Post kindly
That is another thing that one discovers when spends some time in the social media as a creator: Avoid flooding! A script may gather lot of content from diverse places and be eager to publish it all, but the delivery place is a community of users and, specially Mastodon with the Local and Federated Timelines, is sensible of having a big chunk of the scroll kidnaped by a single poster publishing content. Therefor I developed a simple queue where the content to be published is dumped and every schedule run the bot picks up the oldest post and publishes it. This makes the bot to publish once per run, which in my setup is every 15 minutes. For the amount of content that my bot manages, this is more than correct, and in the worst case the queue is caught up in an hour.
Current bot accounts using it
So how is it going? At the moment I use this bot in 4 different accounts, and so far so good!
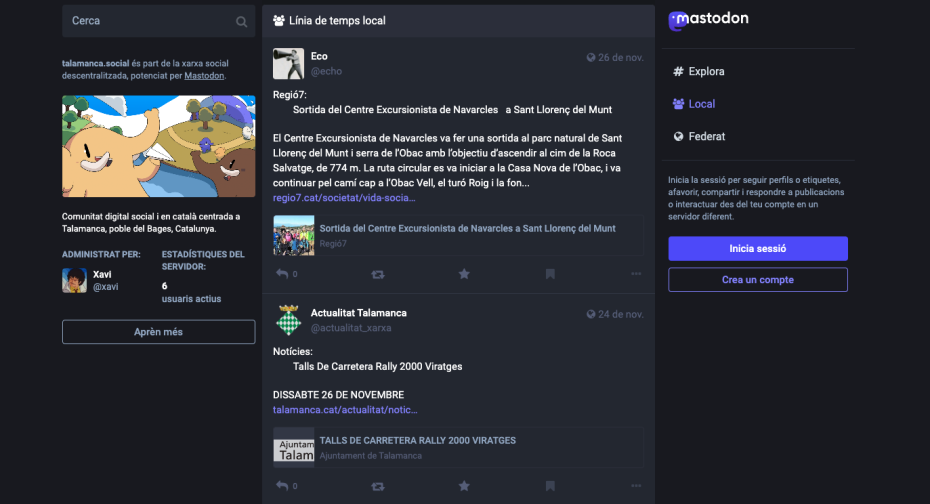
- @actualitat_xarxa@talamanca.social: Meant to gather pseudo-official information about the the Talamanca village. At this point is getting the content from the official Talamanca's webpage's RSS and Twitter account.
- @echo@talamanca.social: Meant to gather press and other non-official content related to Talamanca and the sorroundings, like the other villages close by (Mura, Rocafort, Navarcles...), the Natural Park next to us, ... Here it was very useful the functionality of filtering content per keyword. At this point takes content from a RSS feed and a Mastodon account.
I wanna try it!
Of course! If I were you I'd love to do so too! 😎
Just go to my Github account, I have published there the bot's code as the mastodon-echo-bot under the GNUv3 General Public License, that allows you to use it however you want while you mention me.
Also I wrote extensively the project's README.md explaining how to get it up and running, and don't hesitate to contact me (using the form in the top menu or directly via any of my social media accounts) and I will be happy to assist 😊